
티스토리 뷰
오랜만에 새롭게 알게된 지식 내용을 적어봅니다. (교수님이 시켜서 봤지만 재밌었다!)
Hashgraph는 Leemon Baird 가 2016년 발표한 BFT 기반 합의알고리즘입니다. BFT 합의 알고리즘은 간단히 말하면 우리 중 2/3 이상이 동의하면 okay 하는 내용입니다. Bitcoin의 경우, 51% attack과 같이 단순히 과반 이상의 power를 갖는 집단이 있으면 해당 블록을 따라야 하지만, BFT 합의 알고리즘은 최소 2/3가 동의해야 합니다.
Hashgraph는 이러한 특징을 갖는 BFT 기반의 새로운 합의 알고리즘입니다. 이 합의 알고리즘을 활용하여 만든 것이 Hedera Hashgraph이며, 엄밀히 말하자면 블록체인은 아닙니다. 블록체인은 블록을 모두 연속적으로 이은 것이지만, Hashgraph에서는 DAG 기반으로 노드 간의 그래프를 유지합니다. 이번 글은 Hedera보다는 Hashgraph에서 사용되는 알고리즘 위주로 설명하겠습니다.
사진 출처 :
- Practical Time-Release Blockchain, Sang-Wuk Chae, Jae-Ik Kim and Yongsu Park (https://www.researchgate.net/publication/340842911_Practical_Time-Release_Blockchain)
- Hashgraph Consensus
(https://www.swirlds.com/downloads/SWIRLDS-TR-2016-01.pdf)
- Hashgraph Consensus Youtube
(https://www.youtube.com/watch?v=wgwYU1Zr9Tg)
1. Blockchain vs Hashgraph
대표적인 블록체인인 비트코인의 블록 구조는 아래와 같습니다. 블록은 Header, Body 로 구성되어 있고, Header에는 블록의 메타 데이터인 블록의 생성 시간 (timestamp), 트랜잭션의 merkle root 등의 정보가 기록되어 있습니다.

하지만 Hashgraph의 노드 구조는 아주 단순합니다. 아래와 같이 생성자의 서명, 노드 생성 시간, 트랜잭션 정보, 2개의 해시값으로 구성됩니다. 해당 노드가 블록체인의 블록 역할을 수행합니다.
여기서 사용되는 2개의 해시값은 self parent hash, gossip parent hash 2개입니다. 해당 내용은 이어서 설명드리겠습니다.
일반적인 블록체인은 연결리스트 구조의 블록을 갖고 있지만 해시그래프는 DAG 기반으로 구성됩니다. 일반적인 블록체인은 아래와 같이 연속된 블록이 이전 블록의 해시값을 기록해 나가며 모든 기록을 탐색합니다.
하지만 Hashgraph는 아래와 같이 DAG 기반으로 모든 노드를 탐색해 나갑니다. 노드는 sync라 불리는 과정을 거치며 각자가 알고 있는 정보를 주고 받습니다. 이 때 정보를 주지 않은 사용자의 정보는 아직은 알 수 없지만, sync 시 랜덤하게 정보를 전달할 사용자를 선택하므로, 결국 모든 노드는 모든 정보를 알게 된다는 가정 하에 진행됩니다.
위 그림은 사용자가 모두 A~D까지 4명인 상황이며, 각 사용자는 자신이 아는 정보를 sync를 통해 전달합니다. 예를 들어, D에 생긴 파란색 노드는 C가 D에게 자신의 정보를 전달한 것입니다. 이로써 D는 자신이 알고 있는 정보 (D의 첫번째 노드)와 C로부터 받은 정보 (C의 첫번째 노드)를 합쳐 새로운 정보 (파란색 노드)를 생성합니다. 그리고 파란색 노드는 앞서 말씀드린 2개의 해시값으로 C와 D의 첫 번째 노드의 해시를 갖습니다.
하지만 여기서 C가 거짓된 정보를 전달할 수도 있습니다. C가 거짓된 정보를 D에게 전달했다고 가정하면, D의 파란색 노드에 저장된 C의 첫번째 노드의 해시와 실제 C의 첫번째 노드의 해시는 다른 값을 갖게 됩니다. 그리고 이어서 A가 C에서 sync를 보내어 C의 2번째 노드가 생성되었을 때, C의 2번째 노드는 파란색 노드에 저장된 C의 첫번 째 노드의 해시값과 다른 해시값을 갖습니다. C가 만약 D에게 거짓 정보를 준 것이라면, D가 C의 2번째 노드 정보를 언젠가 알게 되었을 때, C의 첫 번째 노드에 대한 해시값이 다름을 확인할 수 있고, 결국 C는 거짓을 저질렀음을 들키게 됩니다.
모두가 올바른 정보를 sync 한다면, A부터 D는 모두 정보를 주고 받으며, 결국 모두가 같은 그래프를 유지하게 됩니다. 이를 통해 각 사용자는 모든 노드에 저장된 정보를 알 수 있습니다. 이것이 Hashgraph의 기본 흐름입니다.
Hashgraph가 2016년에 발표되었기 때문에 논문에서 제시하고 있는 문제점의 흐름은 주로 bitcoin으로 설명을 이룹니다. 해당 논문에서 문제로 삼고 있는 점은 Bitcoin의 경우, 브랜치 문제가 발생할 수 있다. 즉, 올바르지 않은 포크에 대해 영향력이 더 커서 올바른 브랜치가 무시될 수 있다는 점과 기존의 BFT 기반 합의 알고리즘인 Paxos, Raft의 경우, leader가 존재하기 때문에 leader에 대한 DoS 공격 등이 이루어지면 합의 자체가 불가능하다는 점을 지적하고 있습니다.
그렇기 때문에 논문 제목에도 나와있듯이, Hashgraph 알고리즘은 leader가 없는 BFT 합의 알고리즘입니다. 여기에 기존의 bitcoin에서 이중 지불 문제 같이 문제가 발생된 블록에 포크가 발생했지만, 올바르지 않은 블록으로의 합의가 이루어지는 것을 방지하기 위해 DAG 노드 간 ordering을 할 수 있는 알고리즘을 제시합니다.
2. Core Concepts
논문에서 소개하는 주요 개념으로는 Gossip about Gossip, Virtual Voting, Strongly Seeing, Famous Witness 등이 있습니다.
- Gossip about Gossip : 말 그대로 Gossip 프로토콜을 계속 쓰겠다는 의미입니다. Gossip 프로토콜은 흔히 전염병에 비유하는 프로토콜 방식입니다. 내가 랜덤하게 고른 사람에게 정보를 전달하고, 이 정보가 또 다른 랜덤한 사람에게 전달되는 방식입니다. Hashgraph에서는 Gossip about Gossip 을 통해 사용자가 알고 있는 정보를 계속 퍼트리게 됩니다.
즉, 언젠가는 내 정보도 남이 다 알고, 나도 남의 정보를 다 알게 된다는 개념입니다.
- Virtual Voting : 일반적인 voting 환경을 생각하면, N명의 Mash graph 형태의 네트워크가 존재한다면, 서로가 서로에게 vote 정보를 전달한다면 O(n^2) 이 소요됩니다. 만약 vote 내용에 대한 확인 (송수신 잘 되었는 지 등) 을 추가한다면 O(N^3)이 소요됩니다. 하지만 Virtual Voting은 각 사용자 별로 1번의 vote 내용만 전달하면 되므로 O(N) 이 소요됩니다.
앞서서 말씀드린 바로는 Hashgraph의 특징 중 하나는 지금 내가 알고 있는 정보도 남이 언젠가 알고, 나도 남의 정보를 언젠가 안다는 Gossip about Gossip 프로토콜을 이용한다는 점입니다. 그렇기 때문에 vote 내용이 위조되거나 하지 않는 이상, 올바른 vote 내용을 남들도 알게 됩니다.
즉, Gossip about Gossip 을 통해 모든 사용자가 vote 내용을 결국 알게 된다는 것이 Virtual Voting입니다. vote 내용을 취합하여 결과를 주지 않더라도, Gossip about Gossip 프로토콜로 전달된 내용을 바탕으로 스스로 vote 내용을 계산할 수 있다는 개념입니다.
그렇다면 vote 하고자 하는 것은 무엇일까요. 일반적인 블록체인과 유사하게 합의를 진행할 때 vote를 사용합니다. 일반적인 블록체인에서는 포크가 발생했다면 어디 쪽이 맞는 지 vote를 진행하거나, 블록이 생성되었을 때 맞는 블록인지 확인하는 과정 등에 합의가 사용됩니다. 유사하게 Hashgraph의 vote는 어떤 노드가 Famous 한 지, 노드 간의 ordering이 맞는 지 등에 대해 vote를 진행하게 됩니다. 해당 내용은 이어서 설명하겠습니다.
- Strongly Seeing : 말 그대로 강하게 본다는 뜻입니다. 그렇다면 강하게는 무슨 뜻이고, 본다는 것은 무슨 뜻일까요?
본다 (See) 의 의미는 해당 노드 간에 path가 존재하는 지를 의미합니다. 즉, 아래 그림과 같이 노란색 노드와 주황색 노드 간에 여러 path가 존재합니다.
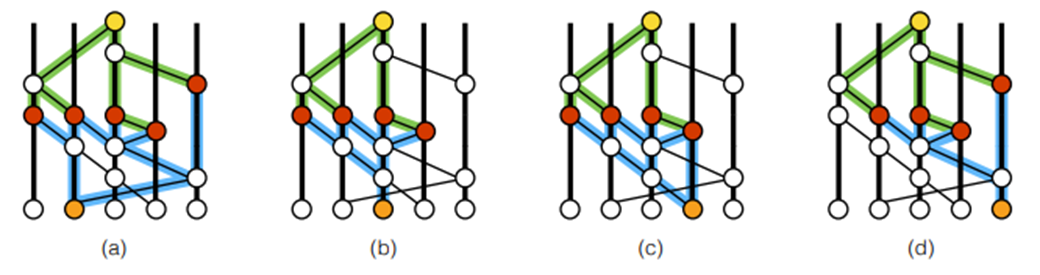
강하게 본다 (Strongly See) 라는 의미는 두 노드 사이에 존재하는 전체 path 를 지나는 사용자가 2/3 이상인 경우를 의미합니다. 해당 path 에 존재하는 노드를 생성한 사용자는 위 그림의 주황색 노드의 정보는 받은 것이기 때문에 위 그림에서 빨간색 노드를 생성한 사용자는 각 주황색 노드의 정보를 알고 있다는 뜻입니다. 여기서의 2/3 기준은 추후 BFT 합의에 사용됩니다.
- Famous Witness : 유명한 증거입니다. 그렇다면 유명한의 뜻은 무엇이고, 증거의 뜻은 무엇일까요?
Witness는 노드 간 ordering의 기준이 되는 특별한 노드입니다. Witness는 이전 라운드 (Witness를 기준으로 나뉘는 구역) Witness 의 2/3 이상을 Strongly See 하는 노드를 의미합니다.
Famous Witness 는 2/3 이상의 사용자가 해당 Witness 정보를 알고 있는 Witness를 의미합니다. 즉, 해당 Witness 가 2/3 이상의 사용자까지 도달하는 path가 존재해야 합니다.
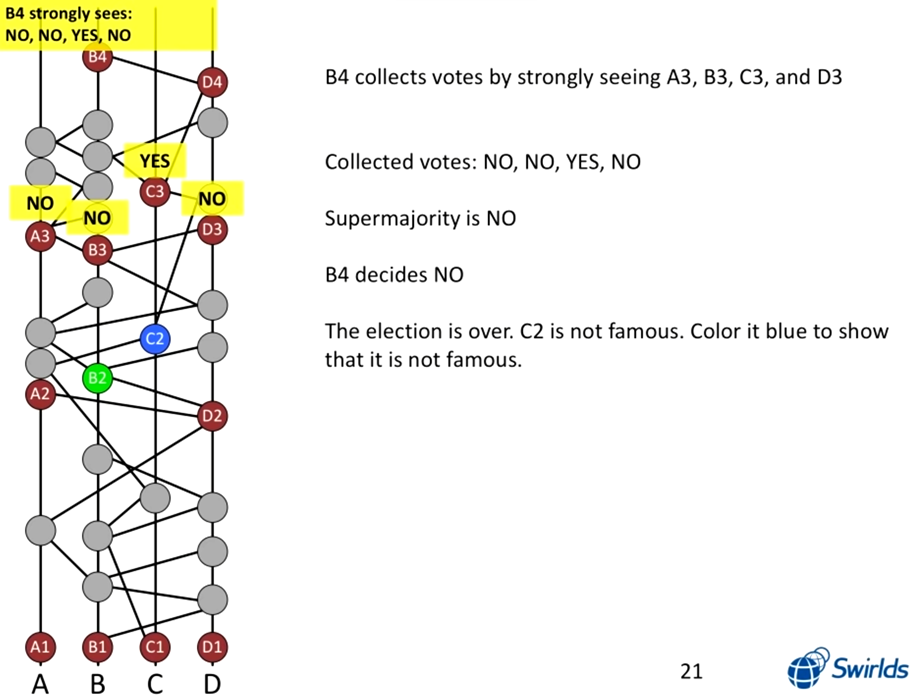
아래 그림을 예시로 든다면, A1 ~ D1, A2 ~ D2, A3 ~ D3, B4, D4 는 모두 Witness 입니다. 그리고 B2는 Famous Witness 입니다. 그 이유는 A3 ~ D3가 생성되기 전에 B2의 정보가 A, B, D 까지 도달하는 경로가 존재합니다. 하지만 C2는 Famous Witness가 아닙니다. 그 이유는 A3 ~ D3가 생성되기 전에 C만이 C2의 정보를 알고 있기 때문입니다.
여기서 앞서 말씀드린 Virtual Voting이 적용됩니다. A3 ~ D3를 대상으로 C2가 Famous Witness인지 아닌지에 대한 vote를 진행한다면, A3, B3, D3는 C2의 정보를 모르므로 (path가 없으므로) No 라는 vote를 합니다. (경로 자체가 없으므로) 그렇다면 해당 투표 내용이 B4, D4에게 전달됩니다. 정확한 투표 알고리즘은 이어서 말씀드리겠지만 B4와 D4 모두 A3 ~ D3까지 경로가 존재하고, No, No, Yes, No 라는 vote 내용을 알게 됩니다. 그렇기 때문에 B4와 D4 모두 C2는 Not Famous Witness 라는 결론을 얻게 됩니다.
이와 비슷한 원리로 Famous Witness 를 선정하게 되며, Famous Witness를 기준으로 노드 간의 순서를 결정하게 됩니다. 간략히 말하자면, Famous Witness를 기준으로 그 이전에 생성된 노드끼리만 order를 정하면 BFT 합의를 기반으로 하기 때문에 2/3 이상의 사용자가 노드의 order를 합의한 것입니다. 따라서 각 사용자는 Famous Witness 를 기준으로 그 사이에 있는 노드의 order를 구한다면, 모든 노드의 order를 구하게 되는 것입니다.
실제 논문에는 fork 개념도 추가되어 있지만, 알고리즘 자체에는 크게 중요하지 않다고 판단되어 넘어가도록 하겠습니다. (양이 너무 많다.....)
3. Consensus
마지막 알고리즘 내용인 Consensus 부분입니다. Hashgraph가 BFT 기반의 leaderless 합의 알고리즘이므로, 합의 알고리즘이 어떻게 동작하는 지 설명하겠습니다.
우선 합의하고자 하는 내용은 다음과 같습니다.
- 어떤 노드가 Witness 인가?
- 그 Witness는 Famous 한가?
- 노드 간의 order는 어떻게 되는가?
이 합의를 진행하기 위해 Hashgraph는 다음과 같은 loop를 돕니다.

사용자는 서로 랜덤하게 sync를 주고 받습니다. 즉, 자신이 알고 있는 정보를 랜덤한 누군가에게 계속 퍼트립니다.
그리고 event라 부르는 노드를 생성합니다. event 생성 시, 처음에 언급했던 노드 구조를 이룹니다.
그리고 Witness와 round를 구분하는 divideRounds, Witness가 Famous 인지 결정하는 decideFame, 노드 간 순서를 판단하는 findOrder 알고리즘을 계속 돌게 됩니다. 이를 통해 최종적인 목표인 위의 합의 내용을 이루게 됩니다.
- divideRounds
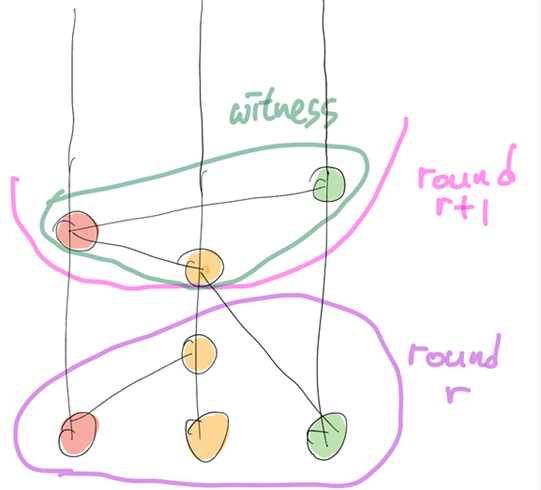
divideRounds 알고리즘은 간단합니다. r을 노드 x의 부모의 라운드 (첫 번째 생긴 노드의 라운드는 1) 의 max라 할 때, x가 2/3 이상의 사용자 (n명) 의 라운드 r에서 Witness와 Strongly See 한다면, x의 라운드는 r+1 입니다. 그리고 x가 r+1 라운드의 첫 번째 노드라면 x는 새로운 Witness가 됩니다.

그림을 예로 들면 아래와 같습니다. 첫 번째 노드들은 모두 부모 노드가 없으므로, Witness입니다. 두 번째 빨간색 노드가 Witness인 첫 번째 노드들과 Strongly see 하는 빨간색의 첫 번째 노드이므로, 라운드는 r+1인 Witness가 됩니다.
- decideFame
decideFame은 라운드를 결정하는 것보다는 아주 복잡합니다. 우선 Fame이 정해지지 않은 노드 x의 라운드가 r일 때,
라운드 r+1의 Witness y에 대해서는 x를 see 하는 지 여부만 판단하고 이를 투표에 반영합니다. r+2의 Witness부터는 x를 Strongly See 하는 지를 판단하고 투표합니다. 만약 투표 결과가 2/3 조건을 만족한다면 투표는 종료됩니다. 투표가 종료되지 않는다면, 다수결을 따르고 다수결 내용을 투표에 반영합니다. 만약 계속 2/3 조건을 만족하지 않으면, 특정 주기인 c 마다 해당 Witness의 signature의 중간값을 투표에 반영합니다. (사실상 coin flip)

간단한 예를 들자면 아래와 같습니다.
노드 간의 연결 관계는 무시하고, 각 라운드의 노드가 A0 ~ D0, A1 ~ D1, A2 ~ D2라고 합시다.
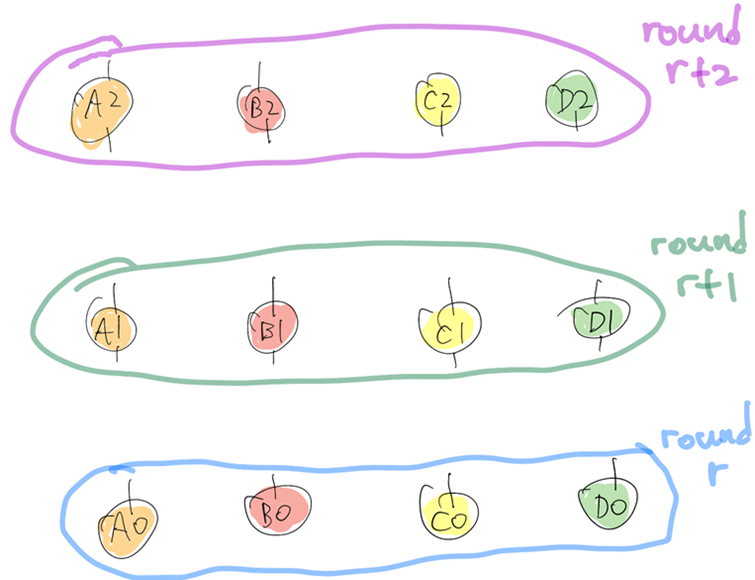

그리고 위와 같이 see, strongly see 관계가 구성되어 있을 때 A0의 fame 여부를 구하는 것을 해보면 다음과 같습니다.
먼저 첫 번째 분기인 d=1인 부분은 현재 r+1 라운드의 Witness를 대상으로 투표를 하는 과정입니다.
그렇기 때문에 이 때는 단순히 see를 하는 지 (즉, path 가 존재하는 지 여부) 를 투표로 합니다.

다음 라운드인 r+2 라운드부터는 이전 투표 내용을 반영합니다.
A2에 대해서 Strongly See 하는 노드는 A1, B1, D1 이고, 해당 노드의 투표 내용은 True 2표, False 1표이므로, 2/3 조건을 만족하지 못합니다. 따라서 A2는 이전 투표 내용으로는 결정하지 못하고 자신은 다수결 의견인 True를 투표로 합니다.
B2는 Strongly See 하는 노드가 A1 ~ D1 이고, 해당 노드의 투표 내용은 True 3표, False 1표이므로 2/3 조건을 만족합니다.
따라서 투표는 종료가 되며, B2가 A0는 Famous 하다는 내용을 알고 있고, Gossip about Gossip 프로토콜으로 해당 내용은 결국 모든 사용자에게 전달되게 됩니다. 따라서 모든 사용자는 A0가 Famous 하다는 것을 알게 됩니다.

만약 A2, B2, C2, D2 모두 vote를 끝내지 못한다면, A3 ~ D3가 A2 ~ D2의 vote 내용으로 투표를 하게 되며, 이것이 지속되더라도, coin flip 단계가 존재하기 때문에 언젠가는 vote가 종료됩니다.
왜냐하면 완벽히 B(n, 0.5)를 따르도록 coin flip을 한다면 다음 loop에서 투표가 종료되지 않을 확률은
P(1/3 * n < X < 2/3 * n)를 만족합니다. 이는 결국 1보다 작으므로, 무한히 반복한다면 끝나지 않을 확률은 0으로 수렴합니다.
- findOrder
findOrder는 노드 간 순서를 정하는 알고리즘입니다. (이전보다 더 보기가 어려운 거 같습니다....)
여기서 새롭게 등장하는 개념이 roundReceived와 consensusTimestamp입니다. roundReceived는 해당 노드를 다른 사용자의 Famous Witness인 순간 알고 있다면, 즉, 사용자의 Famous Witness와 path가 존재한다면 Famous Witness의 라운드를 의미합니다.
ConsensusTimestamp는 노드가 Famous Witness까지 도달하는 path 중 각 사용자 별로 가장 먼저 생성된 노드의 timestamp의 중간값을 의미합니다. 알고리즘 상으로는 이를 기준으로 정렬한다고 합니다. 즉, roundReceived 순으로 노드를 정렬하고, 그 다음으로 ConsensusTimestamp를 기준으로 정렬, 그까지도 정렬이 안 되면 whitened signature (도달한 Witness의 signature의 Xor 값, 사실상 랜덤) 를 기준으로 정렬합니다.

이렇게만 보면 이해가 잘 되지 않아, Hashgraph 유튜브 영상을 참고하면 다음과 같습니다.
아래에서 A2, B2, D2는 Famous Witness, C2는 Not Famous Witness 입니다. 까만 노드는 Famous Witness인 A2, B2, D2까지 모두 도달하는 경로가 존재하므로, 까만 노드의 roundReceived는 2입니다. (A2, B2, D2의 라운드가 2)
그리고 까만 노드의 consensusTimestamp는 A, B, D가 처음 까만 노드의 정보를 알게된 timestamp의 중간값입니다. 즉, A는 까만 노드를 만든 순간, B는 B2일 때, D는 D2일 때 까만 노드의 정보를 받습니다.
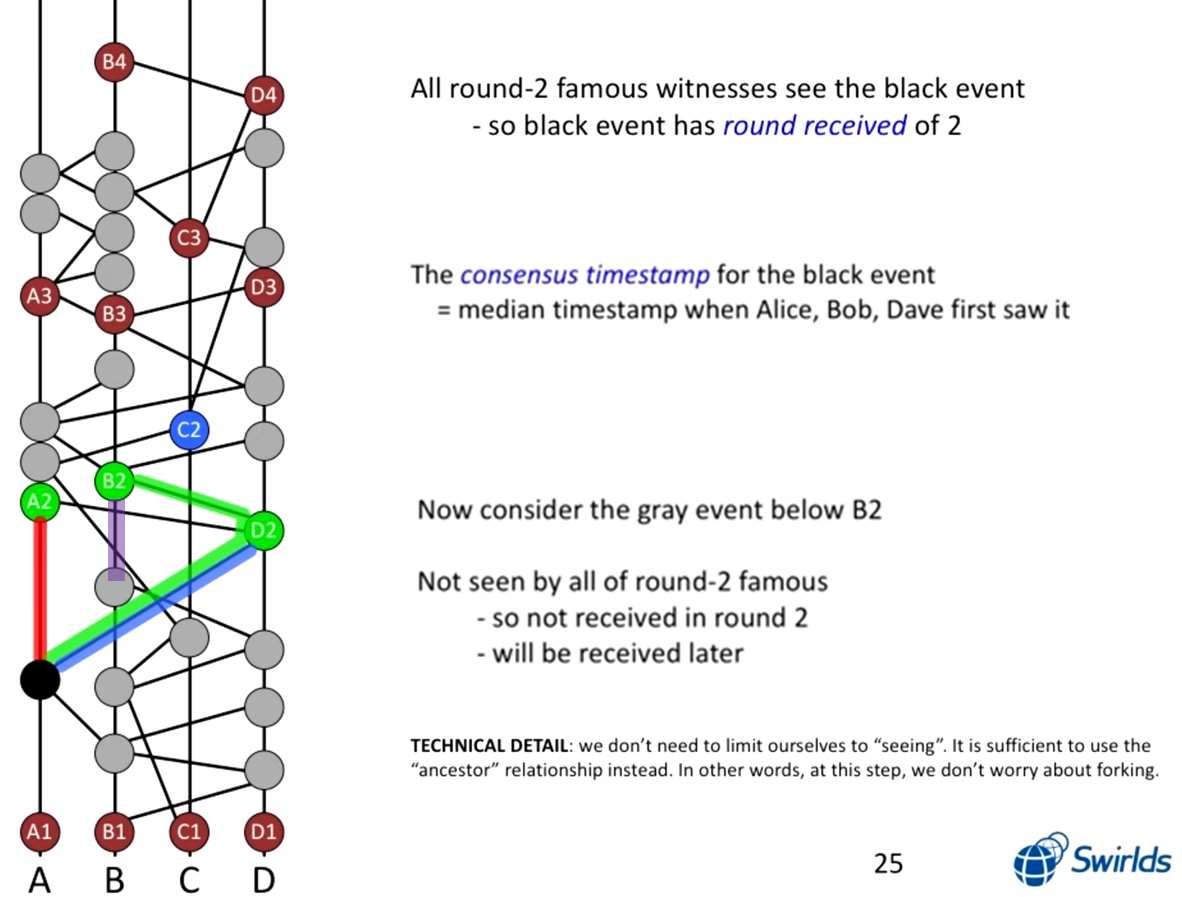
추가적으로 제가 보라색 선을 그은 B2 바로 아래의 노드는 A2, D2까지 도달하는 경로가 존재하지 않으므로, 라운드 3에서 roundReceived가 결정됩니다. 즉, 이 노드의 roundReceived가 3이므로 (A3 ~ D3 중 어떤 것이 Famous인지는 모르지만, 모든 경로 존재하므로 3은 자명) 까만 노드보다는 나중에 생긴 노드임을 의미합니다.
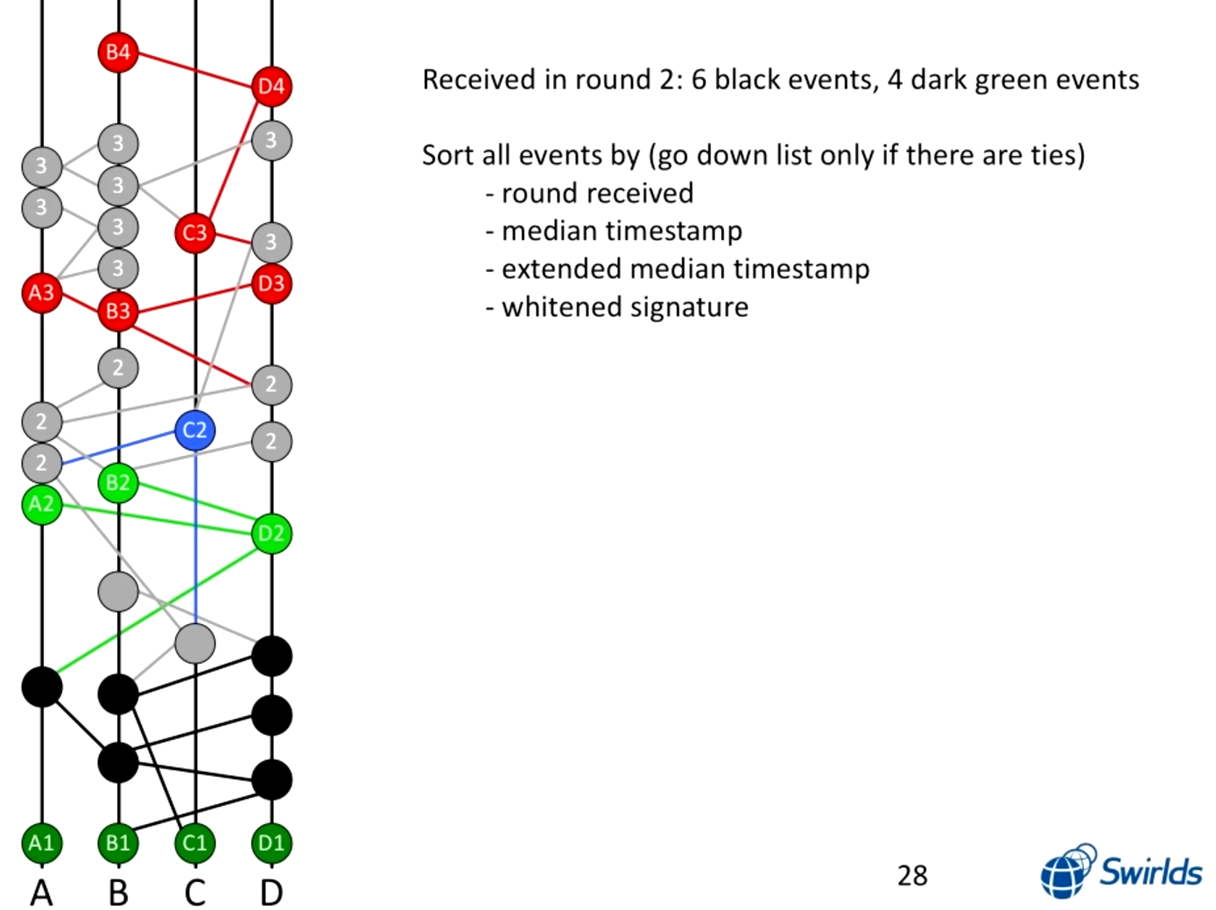
이를 반복하면 위와 같은 그래프를 얻습니다. 여기서 roundReceived가 2로 결정된 것은 까만 노드와 A1 ~ D1 입니다. 해당 노드를 대상으로 consensusTimestamp의 중간값, extended 중간값 (최소, 최대 제외한 중간값), whitened signature (도달하는 witness의 signature의 xor 값, 사실상 랜덤) 순을 기준으로 정렬하면 작은 값부터 큰 값 순으로 노드의 order가 결정됩니다.
현재 위 그림에서는 까만 노드와 A1 ~ D1의 순서만을 결정할 수 있지만, sync가 계속 발생함으로써 모든 노드의 순서를 구할 수 있습니다. 이 때 가장 첫 번째 기준인 roundReceived를 계산하는 기준이 Famous Witness 이므로 결국 Famous Witness를 기준으로 그 사이의 노드 간의 order를 구할 수 있다는 의미가 됩니다.
이러한 방식으로 Hashgraph에서는 노드 간 order를 구할 수 있고, BFT 합의를 이루는 새로운 합의 알고리즘을 제시하였습니다. 당분간 이러한 DAG 방식의 합의 알고리즘, 블록체인 관련한 쪽을 보게 될 것 같습니다. 이외에도 증명이나 fork 내용 등 부가적인 알고리즘 설명이 궁금하신 분은 Hashgraph 논문을 직접 참고하시면 좋을 것 같습니다. 그리고 Hashgraph 유튜브에도 설명이 잘 나와있으니 참고하시면 좋을 것 같습니다.