
티스토리 뷰
Prefix Tuning은 LLM의 전체 파라미터를 조정하는 것이 아닌, 파라미터 중 prefix 부분만 fine tuning 시키는 기법입니다.
LoRA는 LLM에 별도 학습된 레이어를 추가적으로 구축 후, 기존 LLM에 합치는 것이라면, Prefix Tuning은 기존 LLM 자체를 활용해 일부만 파라미터를 수정합니다.
Prefix Tuning에 대한 논문은 아래와 같습니다.
https://arxiv.org/pdf/2101.00190.pdf

해당 논문에 나온 그림처럼, 기존 Transformer 모델은 그대로 두고, prefix 부분만 수정을 진행하여 특정 도메인에 더욱 특화된 fine tuning을 진행하는 것이 목표입니다.
huggingface 튜토리얼을 바탕으로 sentences_allagree 데이터셋을 활용해 금융 뉴스에 대해 positive, negative 인지를 분류하는 fine tuning을 진행해보겠습니다.
즉, 금리가 높아진다. 라는 문장이 있으면 전체적인 금융 상황이 안 좋아진다는 의미이므로 negative 라고 판단하는 모델입니다.
https://huggingface.co/docs/peft/main/en/task_guides/seq2seq-prefix-tuning
Prefix tuning for conditional generation
🤗 Accelerate integrations
huggingface.co
env : google colab
1. 필요 패키지 설치
!pip install -q peft transformers datasets
2. 필요 패키지 import
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, default_data_collator, get_linear_schedule_with_warmup
from peft import get_peft_config, get_peft_model, get_peft_model_state_dict, PrefixTuningConfig, TaskType
from datasets import load_dataset
from torch.utils.data import DataLoader
from tqdm import tqdm
import torch
import os
3. 필요한 전역값 지정
os.environ["TOKENIZERS_PARALLELISM"] = "false"
device = "cuda"
model_name_or_path = "t5-large"
tokenizer_name_or_path = "t5-large"
text_column = "sentence"
label_column = "text_label"
max_length = 128
lr = 1e-2
num_epochs = 5
batch_size = 8
여기서 max_length 는 학습시킬 prefix의 max length 값입니다. 조금 더 정확한 학습을 원한다면 max_length 를 키우거나 epoch 을 늘리는 방안 등을 진행하면 됩니다.
4. sentences_allagree 데이터셋 불러오기
dataset = load_dataset("financial_phrasebank", "sentences_allagree")
dataset = dataset["train"].train_test_split(test_size=0.1)
dataset["validation"] = dataset["test"]
del dataset["test"]
classes = dataset["train"].features["label"].names
dataset = dataset.map(
lambda x: {"text_label": [classes[label] for label in x["label"]]},
batched=True,
num_proc=1,
)
dataset["train"][0] 로 train 용 데이터를 확인하면 다음과 같습니다.
러시아 수출 관세로 핀란드에서 경작이 활성화되고, 러시아에서의 판매도 증가할 것이다. 라는 문장입니다.
구체적으로 어떤 내용인지는 모르지만, 핀란드도 경작이 활성화되고, 러시아도 판매량이 증가하므로 일반적인 경제 관점에서는 positive한 내용으로 판단되며, 실제 label도 positive로 분류되어 있습니다.
5. tokenizer 세팅
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
def preprocess_function(examples):
inputs = examples[text_column]
targets = examples[label_column]
model_inputs = tokenizer(inputs, max_length=max_length, padding="max_length", truncation=True, return_tensors="pt")
labels = tokenizer(targets, max_length=2, padding="max_length", truncation=True, return_tensors="pt")
labels = labels["input_ids"]
labels[labels == tokenizer.pad_token_id] = -100
model_inputs["labels"] = labels
return model_inputs
6. 데이터셋 전처리
processed_datasets = dataset.map(
preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
7. train, eval 용 데이터셋으로 분리
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["validation"]
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
8. peft config 설정
peft_config = PrefixTuningConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, num_virtual_tokens=20)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters() 로 확인 시 다음과 같습니다.
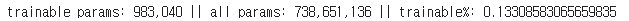
전체 파라미터 중 0.13 % 인 98만여개의 파라미터만 재학습을 진행하게 됩니다.
9. optimizer 설정
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=(len(train_dataloader) * num_epochs),
)
optimizer로는 AdamW 를 이용해 딥러닝 loss function의 최소값을 찾아가게 됩니다.
10. train 진행
model = model.to(device)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for step, batch in enumerate(tqdm(train_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
eval_loss = 0
eval_preds = []
for step, batch in enumerate(tqdm(eval_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
eval_loss += loss.detach().float()
eval_preds.extend(
tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
)
eval_epoch_loss = eval_loss / len(eval_dataloader)
eval_ppl = torch.exp(eval_epoch_loss)
train_epoch_loss = total_loss / len(train_dataloader)
train_ppl = torch.exp(train_epoch_loss)
print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
tqdm 은 패키지 설치 시 얼마나 진행되었는 지에 대해 bar 형태로 진행상황을 나타내주는 패키지입니다. 시각적으로 필요없다면 제외하고 사용해도 됩니다.
11. 학습된 모델 평가
correct = 0
total = 0
for pred, true in zip(eval_preds, dataset["validation"]["text_label"]):
if pred.strip() == true.strip():
correct += 1
total += 1
accuracy = correct / total * 100
print(f"{accuracy=} % on the evaluation dataset")
print(f"{eval_preds[:10]=}")
print(f"{dataset['validation']['text_label'][:10]=}")
validation 데이터셋으로 학습된 모델을 평가해본 결과 96% 정도의 정확도를 얻었습니다.
12. 학습된 모델 테스트
inputs = tokenizer(
"The Lithuanian beer market made up 14.41 million liters in January , a rise of 0.8 percent from the year-earlier figure , the Lithuanian Brewers ' Association reporting citing the results from its members .",
return_tensors="pt",
)
with torch.no_grad():
inputs = {k: v.to(device) for k, v in inputs.items()}
outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=10)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
리투아니아의 맥주 시장이 전년 대비 0.8 % 증가했다는 내용입니다. 학습된 모델을 바탕으로 positive 결과를 얻었으며, 실제 내용도 일반적인 경제 관점에서는 판매량이 증가했으므로 positive로 판단됩니다.
13. 결론
prefix tuning은 기존 LLM 파라미터 튜닝을 진행하면서도 prefix 라는 일부만 파라미터 수정을 진행하여도 fine tuning이 가능하다는 의의를 갖습니다. 따라서 LLM의 모든 파라미터를 튜닝하는 것보다 더 효율적으로 fine tuning을 이뤄낼 수 있습니다.
'LLM > Fine Tuning' 카테고리의 다른 글
| Prompt Tuning (0) | 2024.04.14 |
|---|---|
| P-Tuning (0) | 2024.04.14 |
| LoRA (0) | 2024.04.14 |
| PEFT (1) | 2024.04.14 |