
티스토리 뷰
P-Tuning은 아래 논문에서 처음 소개되었습니다.
https://arxiv.org/pdf/2103.10385.pdf
논문 제목이 GPT Understands, too 인데 그 이유는 GPT 모델의 경우, 논문이 나온 당시 GPT 모델은 NLI (Natural Language Inference), AE (Aspect Extraction) 등 텍스트 간의 추론에서 성능이 모자랐었지만, 이는 해당 모델이 이해하도록 prompt를 구성하는 것이 어렵기 때문입니다. 따라서 P-Tuning은 prompt를 GPT가 이해하기 쉽게 Tuning 한다는 의미를 갖습니다.

논문에 나온 해당 그림처럼 Prompt Encoder 부분을 이용해 GPT가 더욱 prompt를 잘 이해하도록 입력 자체를 변환시키겠다는 것이 해당 논문의 주 목적입니다.
P-Tuning에 대한 huggingface 튜토리얼은 아래와 같습니다.
https://huggingface.co/docs/peft/main/en/task_guides/ptuning-seq-classification
P-tuning for sequence classification
🤗 Accelerate integrations
huggingface.co
huggingface의 P-Tuning 튜토리얼을 이용해 glue의 mrpc 데이터셋에 대해 두 문장이 관련성이 있는 문장인지 아닌지를 판단하도록 fine tuning을 진행하겠습니다.
1. 필요 패키지 다운
!pip install -q peft transformers datasets evaluate
2. 필요 패키지 import
from transformers import AutoModelForSequenceClassification, AutoTokenizer, DataCollatorWithPadding, TrainingArguments, Trainer
from peft import get_peft_config, get_peft_model, get_peft_model_state_dict, set_peft_model_state_dict, PeftType, PromptEncoderConfig
from datasets import load_dataset
import evaluate
import torch
3. 전역 설정값 지정
model_name_or_path = "roberta-large"
task = "mrpc"
num_epochs = 3
lr = 1e-3
batch_size = 32
huggingface 튜토리얼의 경우 20 에폭으로 학습을 진행했지만, 빠른 학습을 위해 3 에폭만 진행하였습니다.
4. mrpc 데이터셋 로드
dataset = load_dataset("glue", task)
dataset["train"][0] 로 어떻게 생긴 데이터셋인지 확인해보면 다음과 같습니다.
sentence1을 해석하면
암로지는 자신이 '증인'이라고 부르는 자신의 형이 자신의 증거를 의도적으로 왜곡했다고 비난했습니다.
sentence2를 해석하면
암로지는 그를 단지 "증인"이라고 언급하면서 그의 형이 자신의 증거를 고의적으로 왜곡했다고 비난했습니다.
로 해석됩니다. 따라서 둘은 동일한 의미를 갖고 있으므로 label = 1이 관련성 있는 문장이다 라는 것을 알 수 있습니다.
해당 데이터셋에 대한 문서 확인 결과, 0이면 관련 없는 것, 1이면 관련 있는 것으로 나옵니다.
https://www.tensorflow.org/datasets/catalog/glue#gluemrpc
접착제 | TensorFlow Datasets
이 페이지는 Cloud Translation API를 통해 번역되었습니다. 접착제 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. 일반 언어 이해 평가 벤치마크( https://gluebenchmar
www.tensorflow.org
5. 평가 metric 생성
import numpy as np
metric = evaluate.load("glue", task)
def compute_metrics(eval_pred) :
preds, labels = eval_pred
preds = np.argmax(preds, axis = 1)
return metric.compute(predictions=preds, references=labels)
6. tokenizer 생성
if any(k in model_name_or_path for k in ("gpt", "opt", "bloom")) :
padding_side = "left"
else :
padding_side = "right"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side=padding_side)
if getattr(tokenizer, "pad_token_id") is None :
tokenizer.pad_token_id = tokenizer.eos_token_id
7. 데이터셋 tokenization
def tokenize_function(examples) :
outputs = tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=None)
return outputs
tokenized_datasets = dataset.map(tokenize_function, batched=True, remove_columns=["idx", "sentence1", "sentence2"])
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
8. tokenization된 데이터셋을 학습에 맞게 패딩 진행
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, padding="longest")
9. peft 모델 설정
peft_config = PromptEncoderConfig(task_type="SEQ_CLS", num_virtual_tokens=20, encoder_hidden_size=128)
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters() 로 확인 결과, 전체 파라미터의 0.37 % 만 파라미터 조정이 발생됩니다.
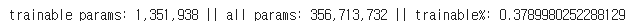
10. train 을 위한 설정값 지정
training_args = TrainingArguments(
output_dir = "roberta-large-peft-p-tuning",
learning_rate=lr,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=num_epochs,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
)
11. trainer 생성
trainer = Trainer(
model = model,
args = training_args,
train_dataset = tokenized_datasets['train'],
eval_dataset = tokenized_datasets['test'],
tokenizer = tokenizer,
data_collator = data_collator,
compute_metrics = compute_metrics,
)
12. 학습 진행
trainer.train()
위까지 진행 시 colab 기준 왼쪽 파일 아이콘 클릭 시, 학습된 모델이 생성됩니다. (output_dir 에서 지정한 위치)
해당 모델을 로드하여 테스트를 진행합니다.
13. 학습된 모델 로드
from peft import PeftModel, PeftConfig
peft_model_id = "./roberta-large-peft-p-tuning/checkpoint-345"
config = PeftConfig.from_pretrained(peft_model_id)
inference_model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = PeftModel.from_pretrained(inference_model, peft_model_id)
14. 테스트값 생성 및 tokenization
classes = ["not equivalent", "equivalent"]
sentence1 = "Coast redwood trees are the tallest trees on the planet and can grow over 300 feet tall."
sentence2 = "The coast redwood trees, which can attain a height of over 300 feet, are the tallest trees on earth."
inputs = tokenizer(sentence1, sentence2, truncation=True, padding="longest", return_tensors="pt")
15. 테스트
with torch.no_grad():
outputs = model(**inputs).logits
print(outputs)
paraphrased_text = torch.softmax(outputs, dim=1).tolist()[0]
for i in range(len(classes)):
print(f"{classes[i]}: {int(round(paraphrased_text[i] * 100))}%")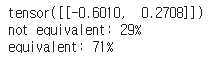
두 문장이 동일한지 여부가 71% 로 결정되었습니다. 실제 huggingface 튜토리얼 상에서는 96% 로 결정됩니다. 빠른 학습을 위해 에폭을 낮추었지만 어느 정도 성능이 잘 나오는 것을 알 수 있습니다.
16. 결론
P-Tuning은 LLM 파라미터 자체를 조정하는 것이 아닌, 프롬프트를 LLM이 더 잘 이해할 수 있도록 튜닝하는 것에서 앞선 다른 fine tuning 기법들과 차이가 있습니다. 이런 방식으로도 fine tuning을 할 수 있다는 것이 흥미롭습니다.
'LLM > Fine Tuning' 카테고리의 다른 글
| Prompt Tuning (0) | 2024.04.14 |
|---|---|
| Prefix Tuning (0) | 2024.04.14 |
| LoRA (0) | 2024.04.14 |
| PEFT (1) | 2024.04.14 |