
티스토리 뷰
Prompt Tuning은 아래 논문에서 소개된 내용입니다.
https://arxiv.org/pdf/2104.08691.pdf
Prefix Tuning과 유사한 방식으로, 각 task 별로 기존 LLM 의 일부를 fine tuning 하여 학습한다는 내용입니다.

Prompt Tuning에 대한 huggingface 튜토리얼은 아래와 같습니다.
https://huggingface.co/docs/peft/main/en/task_guides/clm-prompt-tuning
Prompt tuning for causal language modeling
🤗 Accelerate integrations
huggingface.co
해당 내용을 바탕으로 RAFT의 twitter_complaints 데이터셋에 대해 해당 트윗이 불평하는 트윗인지 아닌지를 판단하도록 fine tuning 하도록 하겠습니다.
1. 필요 패키지 설치
!pip install -q peft transformers datasets
2. 필요 패키지 import
from transformers import AutoModelForCausalLM, AutoTokenizer, default_data_collator, get_linear_schedule_with_warmup
from peft import get_peft_config, get_peft_model, PromptTuningInit, PromptTuningConfig, TaskType, PeftType
import torch
from datasets import load_dataset
import os
from torch.utils.data import DataLoader
from tqdm import tqdm
3. 전역 설정값 지정
device = "cuda"
model_name_or_path = "bigscience/bloomz-560m"
tokenizer_name_or_path = "bigscience/bloomz-560m"
dataset_name = "twitter_complaints"
text_column = "Tweet text"
label_column = "text_label"
max_length = 64
lr = 3e-2
num_epochs = 50
batch_size = 8
4. 데이터셋 로드
dataset = load_dataset("ought/raft", dataset_name)
dataset["train"][0] 로 어떤 구성인지 살펴보면 다음과 같습니다.
해석하면 아니. 내 첫번째 직장이다. 라는 것인데 이것이 불평은 아닌 것으로 보입니다.
아래 raft 데이터셋 내용을 확인해보면 twitter_complaints 는 label 2개로 구성이 되어 있고 1은 complaint, 2는 not complaint로 구분됩니다.
https://huggingface.co/datasets/ought/raft
ought/raft · Datasets at Hugging Face
A patient with psoriasis is described who had an abnormal response to the glucose tolerance test without other evidence of diabetes and then developed postprandial hyperglycemia and glycosuria during a period of topical administration of a corticosteroid c
huggingface.co
5. 데이터셋 라벨링
classes = [k.replace("_", " ") for k in dataset["train"].features["Label"].names]
dataset = dataset.map(
lambda x: {"text_label": [classes[label] for label in x["Label"]]},
batched=True,
num_proc=1,
)
6. tokenizer 생성
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
7. 데이터셋 tokenization
def preprocess_function(examples):
batch_size = len(examples[text_column])
inputs = [f"{text_column} : {x} Label : " for x in examples[text_column]]
targets = [str(x) for x in examples[label_column]]
model_inputs = tokenizer(inputs)
labels = tokenizer(targets)
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i] + [tokenizer.pad_token_id]
#print(i, sample_input_ids, label_input_ids)
model_inputs["input_ids"][i] = sample_input_ids + label_input_ids
labels["input_ids"][i] = [-100] * len(sample_input_ids) + label_input_ids
model_inputs["attention_mask"][i] = [1] * len(model_inputs["input_ids"][i])
#print(model_inputs)
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i]
model_inputs["input_ids"][i] = [tokenizer.pad_token_id] * (
max_length - len(sample_input_ids)
) + sample_input_ids
model_inputs["attention_mask"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[
"attention_mask"
][i]
labels["input_ids"][i] = [-100] * (max_length - len(sample_input_ids)) + label_input_ids
model_inputs["input_ids"][i] = torch.tensor(model_inputs["input_ids"][i][:max_length])
model_inputs["attention_mask"][i] = torch.tensor(model_inputs["attention_mask"][i][:max_length])
labels["input_ids"][i] = torch.tensor(labels["input_ids"][i][:max_length])
model_inputs["labels"] = labels["input_ids"]
return model_inputs
processed_datasets = dataset.map(
preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
8. 학습용, 평가용 데이터셋으로 분리
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["test"]
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
9. peft 모델 설정
peft_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM,
prompt_tuning_init=PromptTuningInit.TEXT,
num_virtual_tokens=8,
prompt_tuning_init_text="Classify if the tweet is a complaint or not:",
tokenizer_name_or_path=model_name_or_path,
)
10. peft 모델 생성
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters() 로 확인하면 다음과 같습니다.
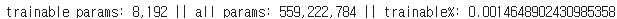
전체 파라미터 중 0.001 % 인 8192 개의 파라미터만 튜닝하면 됩니다. 이전까지 나온 모든 기법 중 가장 적은 비율의 파라미터만을 조정합니다.
11. train 을 위한 optimizer 지정
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=(len(train_dataloader) * num_epochs),
)
12. 학습 시작
model = model.to(device)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for step, batch in enumerate(tqdm(train_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
eval_loss = 0
eval_preds = []
for step, batch in enumerate(tqdm(eval_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
eval_loss += loss.detach().float()
eval_preds.extend(
tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
)
eval_epoch_loss = eval_loss / len(eval_dataloader)
eval_ppl = torch.exp(eval_epoch_loss)
train_epoch_loss = total_loss / len(train_dataloader)
train_ppl = torch.exp(train_epoch_loss)
print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
13. 학습 모델에 대한 테스트
inputs = tokenizer(
f'{text_column} : {"@nationalgridus I have no water and the bill is current and paid. Can you do something about this?"} Label : ',
return_tensors="pt",
)
model.to(device)
with torch.no_grad():
inputs = {k: v.to(device) for k, v in inputs.items()}
outputs = model.generate(
input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], max_new_tokens=10, eos_token_id=3
)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
트윗 내용은 어떤 문제에 대해 뭔가를 해달라고 하고 있습니다. 불평하는 것으로 보이고, 학습 모델에 적용한 결과 complaint로 판명되었습니다.
14. 결론
Prompt Tuning은 prefix tuning 처럼 일부 파라미터를 튜닝해 학습하는 기법이지만, prefix tuning에 비해 매우 적은 파라미터 튜닝만을 진행한 점이 흥미롭습니다.
'LLM > Fine Tuning' 카테고리의 다른 글
| P-Tuning (0) | 2024.04.14 |
|---|---|
| Prefix Tuning (0) | 2024.04.14 |
| LoRA (0) | 2024.04.14 |
| PEFT (1) | 2024.04.14 |